Before I start this post, let me just say I’m using an old version of the Infragistics XamDataGrid for this post, version 10.3. Hence this may have been changed in subsequent releases, but as I have a legacy application to support, that’s the version we’re using.
I want to display hierarchical data within the grid, so let’s start with a sample view model.
public class EmployeeViewModel
{
public EmployeeViewModel()
{
Manages = new ObservableCollection<EmployeeViewModel>();
}
public string Name { get; set; }
public ObservableCollection<EmployeeViewModel> Manages { get; set; }
}
Note: I’ve not bothered with supporting the INotifyPropertyChanged interface etc. this is bare bones just to demonstrate the concepts
So the EmployeeViewModel represents a basic employee hierarchy. Here’s a factory that creates the same data, which should make the hierarchy quite obvious.
public static class EmployeeViewModelFactory
{
public static ObservableCollection<EmployeeViewModel> Create()
{
var employees = new ObservableCollection<EmployeeViewModel>();
var bob = new EmployeeViewModel {Name = "Bob"};
var bill = new EmployeeViewModel { Name = "Bill" };
var fred = new EmployeeViewModel { Name = "Fred" };
var alfred = new EmployeeViewModel { Name = "Alfred" };
var jim = new EmployeeViewModel { Name = "Jim" };
var jeff = new EmployeeViewModel { Name = "Jeff" };
var craig = new EmployeeViewModel { Name = "Craig" };
bob.Manages.Add(bill);
bob.Manages.Add(fred);
alfred.Manages.Add(jim);
jim.Manages.Add(jeff);
employees.Add(bob);
employees.Add(alfred);
employees.Add(craig);
return employees;
}
}
Now it’s pretty easy to configure the XamDataGrid to handle this data, I’ll manually create the fields, so here’s the XAML
<igDP:XamDataGrid GroupByAreaLocation="None" DataSource="{Binding}">
<igDP:XamDataGrid.FieldLayoutSettings>
<igDP:FieldLayoutSettings ExpansionIndicatorDisplayMode="CheckOnDisplay"
AutoGenerateFields="False"/>
</igDP:XamDataGrid.FieldLayoutSettings>
<igDP:XamDataGrid.FieldLayouts>
<igDP:FieldLayout>
<igDP:FieldLayout.Fields>
<igDP:Field Name="Name" />
<igDP:Field Name="Manages" Visibility="Hidden" />
</igDP:FieldLayout.Fields>
</igDP:FieldLayout>
</igDP:XamDataGrid.FieldLayouts>
</igDP:XamDataGrid>
This will produce the following UI
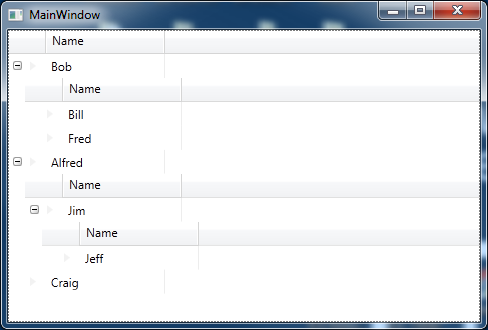
This is great, but I don’t really want the subheadings for this data and I’d prefer if the child columns lined up with the parents, more like a treeview and this is where things get a little tricky.
Removing the child item headers
To remove the headers we use
<igDP:FieldLayout.Settings> <igDP:FieldLayoutSettings LabelLocation="Hidden" /> </igDP:FieldLayout.Settings>
This code is placed within the FieldLayout section, but ofcourse if you do this in the one and only FieldLayout you’ll also lose the heading of the parent row.
So what you might try is to implement a second FieldLayout section as per
<igDP:XamDataGrid.FieldLayouts>
<igDP:FieldLayout>
<igDP:FieldLayout.Fields>
<igDP:Field Name="Name" />
<igDP:Field Name="Manages" Visibility="Hidden" />
</igDP:FieldLayout.Fields>
</igDP:FieldLayout>
<igDP:FieldLayout>
<igDP:FieldLayout.Settings>
<igDP:FieldLayoutSettings LabelLocation="Hidden" />
</igDP:FieldLayout.Settings>
<igDP:FieldLayout.Fields>
<igDP:Field Name="Name" />
<igDP:Field Name="Manages" Visibility="Hidden" />
</igDP:FieldLayout.Fields>
</igDP:FieldLayout>
</igDP:XamDataGrid.FieldLayouts>
But this will not solve the problem and here’s the gotcha…
From my understanding the FieldLayout is based upon the the field names on your objects and hence as the EmployeeViewModel is used throughout only the first FieldLayout is ever applied to the view of the data. For example even if you changed all top level employees in the example to be of type ManagerViewModel (with this being an exact copy of EmployeeViewModel, and obviously fixing the code to handle this in the factory etc., you would still find only the first FieldLayout used. On the other hand if we had something like
public class ManagerViewModel
{
public ManagerViewModel()
{
Manages = new ObservableCollection<EmployeeViewModel>();
}
public string Name { get; set; }
public ObservableCollection<EmployeeViewModel> Manages { get; set; }
}
public class EmployeeViewModel
{
public EmployeeViewModel()
{
DepartmentManages = new ObservableCollection<EmployeeViewModel>();
}
public string Name { get; set; }
public ObservableCollection<EmployeeViewModel> DepartmentManages { get; set; }
}
public static class EmployeeViewModelFactory
{
public static ObservableCollection<ManagerViewModel> Create()
{
var employees = new ObservableCollection<ManagerViewModel>();
var bob = new ManagerViewModel { Name = "Bob" };
var bill = new EmployeeViewModel { Name = "Bill" };
var fred = new EmployeeViewModel { Name = "Fred" };
var alfred = new ManagerViewModel { Name = "Alfred" };
var jim = new EmployeeViewModel { Name = "Jim" };
var jeff = new EmployeeViewModel { Name = "Jeff" };
var craig = new ManagerViewModel { Name = "Craig" };
bob.Manages.Add(bill);
bob.Manages.Add(fred);
alfred.Manages.Add(jim);
jim.DepartmentManages.Add(jeff);
employees.Add(bob);
employees.Add(alfred);
employees.Add(craig);
return employees;
}
}
and the XAML might look like
<igDP:XamDataGrid GroupByAreaLocation="None" DataSource="{Binding}">
<igDP:XamDataGrid.FieldLayoutSettings>
<igDP:FieldLayoutSettings ExpansionIndicatorDisplayMode="CheckOnDisplay"
AutoGenerateFields="False"/>
</igDP:XamDataGrid.FieldLayoutSettings>
<igDP:XamDataGrid.FieldLayouts>
<igDP:FieldLayout>
<igDP:FieldLayout.Fields>
<igDP:Field Name="Name" />
<igDP:Field Name="Manages" Visibility="Hidden" />
</igDP:FieldLayout.Fields>
</igDP:FieldLayout>
<igDP:FieldLayout>
<igDP:FieldLayout.Settings>
<igDP:FieldLayoutSettings LabelLocation="Hidden" />
</igDP:FieldLayout.Settings>
<igDP:FieldLayout.Fields>
<igDP:Field Name="Name" />
<igDP:Field Name="DepartmentManages" Visibility="Hidden" />
</igDP:FieldLayout.Fields>
</igDP:FieldLayout>
</igDP:XamDataGrid.FieldLayouts>
</igDP:XamDataGrid>
We would now see the following
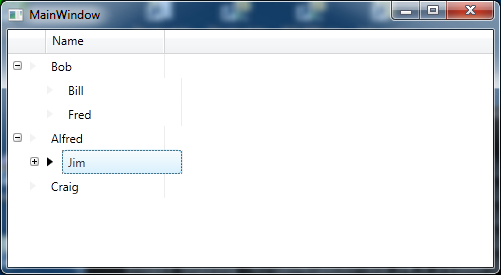
Not ideal, but we now know why EmployeeViewModel referencing itself in the Manages property fails to work. However we now have some more oddities, including the fact that the column lines are out of alignment. I’ll be writing another post on my attempts to resolve this.
References
Can I choose a field layout based on data Type?
FieldLayout Class